ElasticSearch是一个开源的分布式,RESTful风格的搜索和数据分析引擎。
简介
一个分布式的实时文档存储,每个字段可以被索引与搜索; 一个分布式实时分析搜索引擎; 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
以下命令均在ES7.7.0版本下执行。
基本概念
全文搜索
全文搜索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置。用户通过关键词进行搜索时,检索程序返回所有匹配结果。
倒排索引
根据文档内容进行分词,然后映射存在词的文档编号。而正向索引是通过为文档编号建立索引,然后通过编号查找文档内容。
节点&集群
ES本质为一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个ES实例。单个ES实例被称为一个节点(Node),一组节点构成一个集群(Cluster)。
索引(Index)
ES数据管理的顶层单位,相当于关系型数据库中的数据库。
文档(Document)
索引(index)里面的单条记录被称为文档,多个文档构成索引。文档使用JSON格式标识,同一个Index里的文档结构最好保持相同,便于提供搜索效率。
类型(Type)
文档可以分组,如employee这个索引里面的文档可以按照部门分组,也可以按照职级分组。是一种虚拟的逻辑分组,用于过滤文档。类似于数据库中的表,不同的类型应该有相似的结构,完全不同的数据应该存为两个索引,而不是同一个索引里面的两个类型(虽然可以做到)--效率低
文档元数据(Document Metadata)
文档元数据有3个,分别为_index,_type,_id。用于唯一表示一个文档,其中_index标识文档存放在那个索引,_type标识文档的逻辑分组,_id为文档的唯一标识。
字段(Fields)
每个文档都类似于JSON格式,包含了许多字段,每个字段都有对应的值,多个字段组成了一个文档。类似于数据库数据表中的字段。
基本操作-增删改查
创建,添加
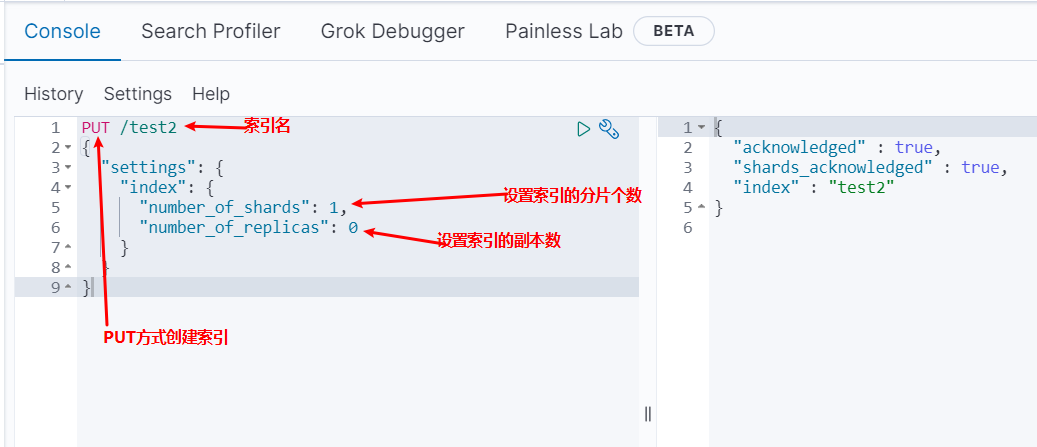
创建索引index
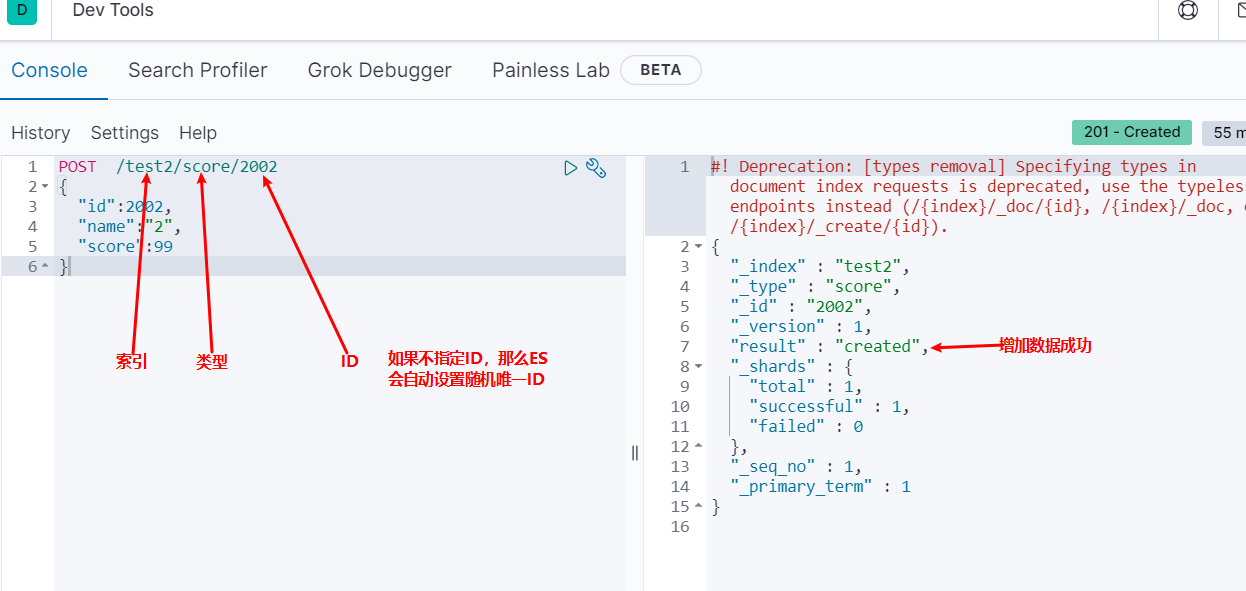
添加文档document
删除
删除索引index
删除类型Type也可以使用该方法。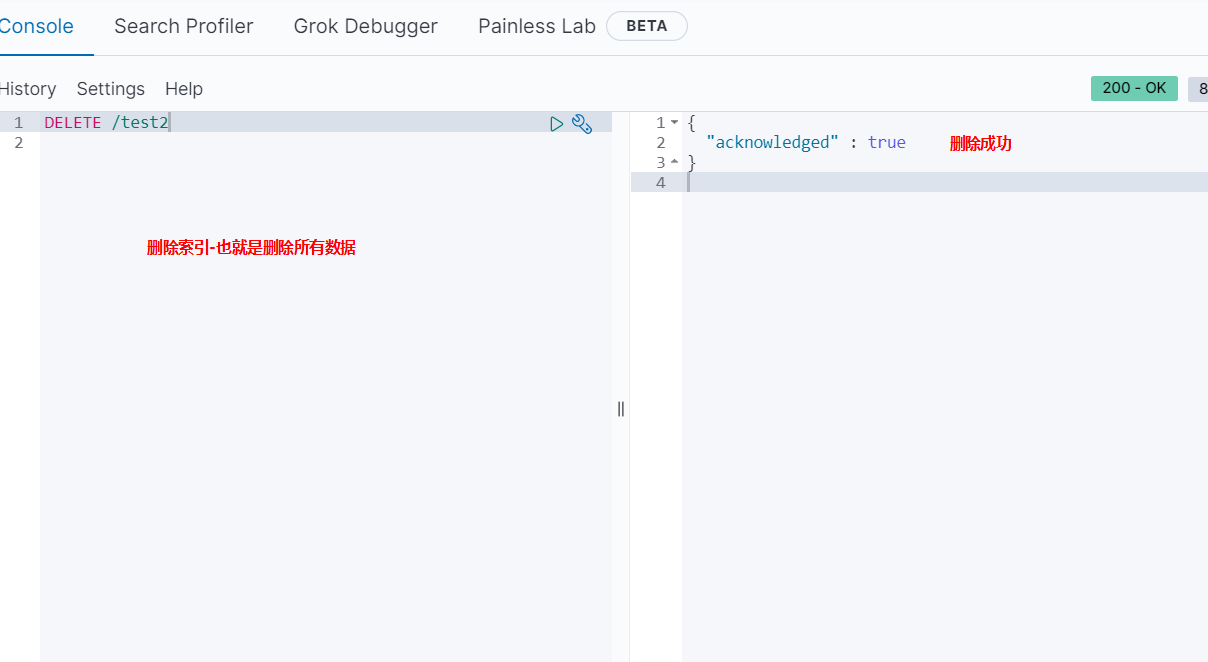
删除文档document
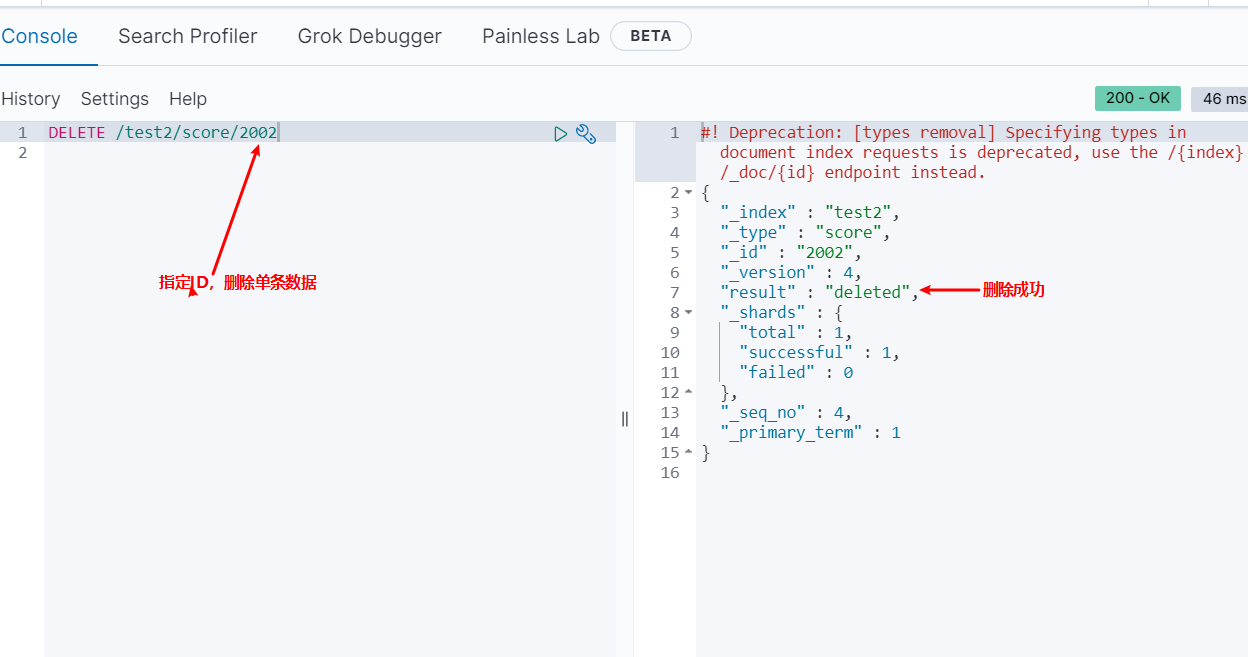
更改
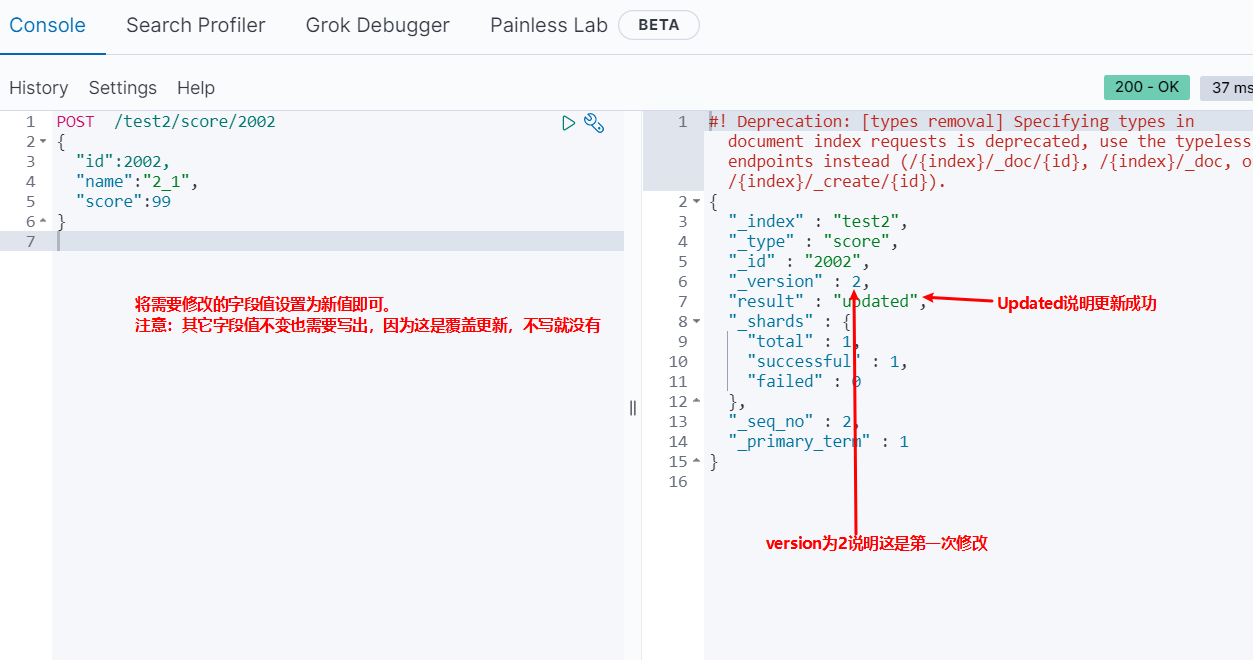
覆盖更新
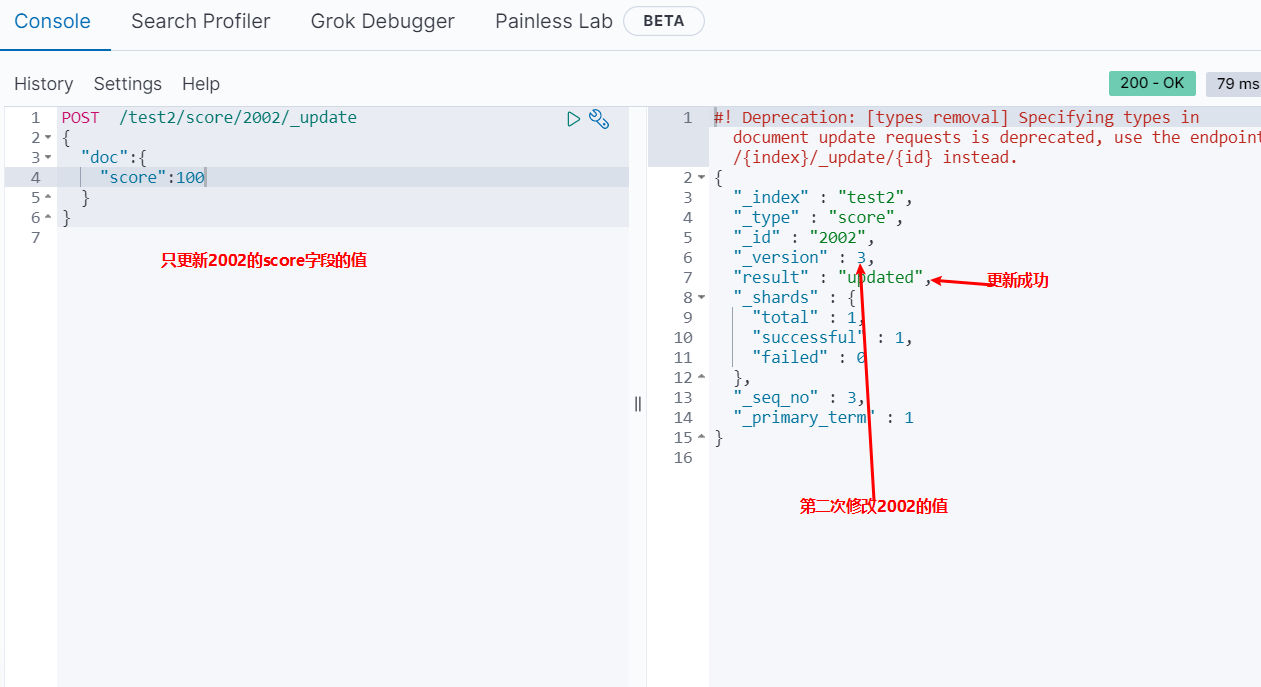
局部更新
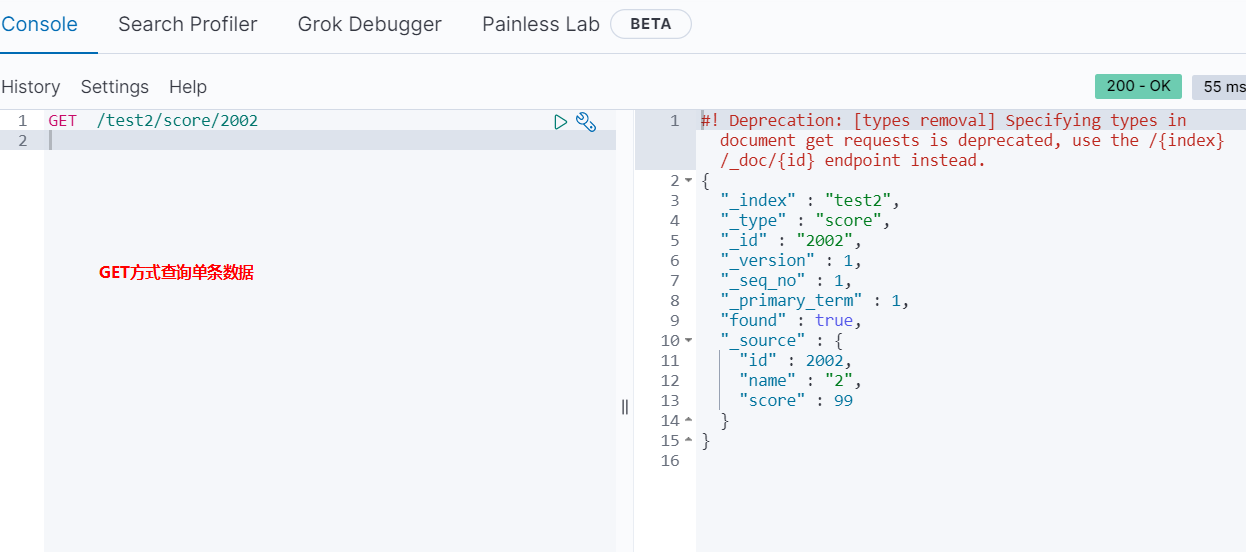
查询
单个文档查询
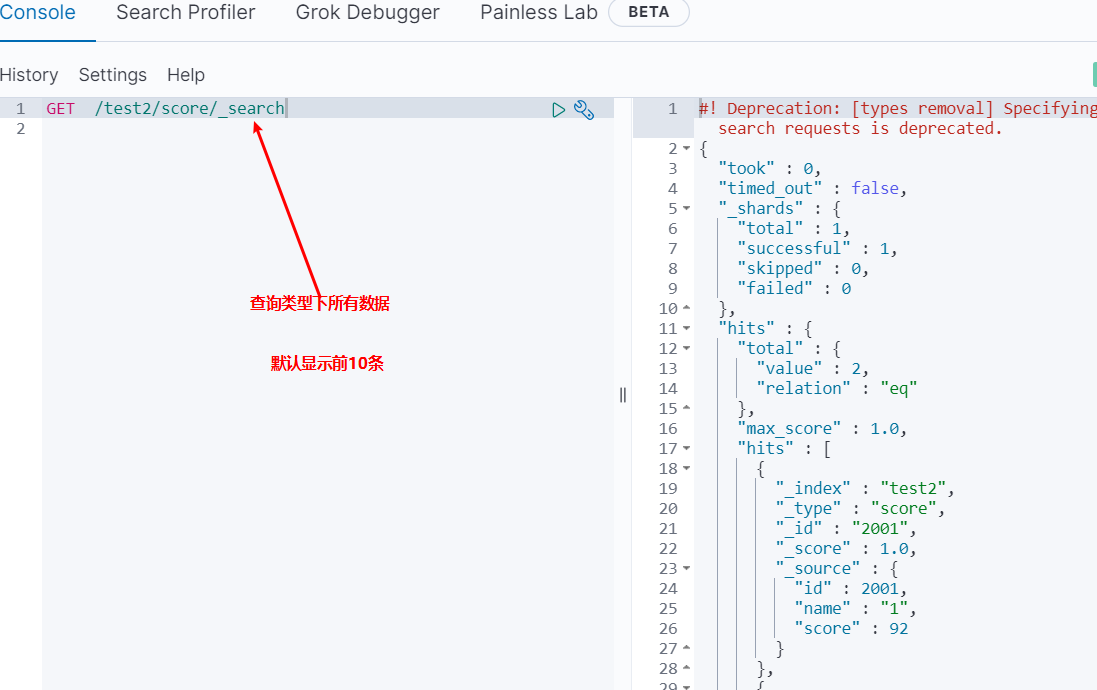
同类型文档查询
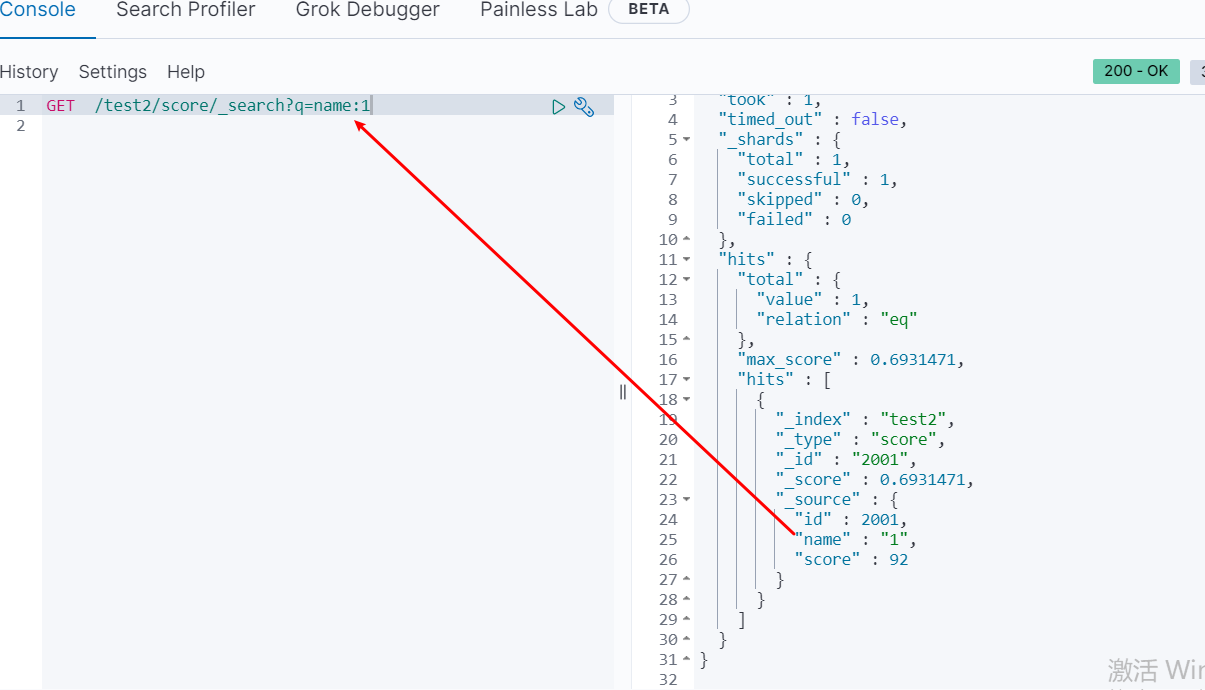
根据字段查询
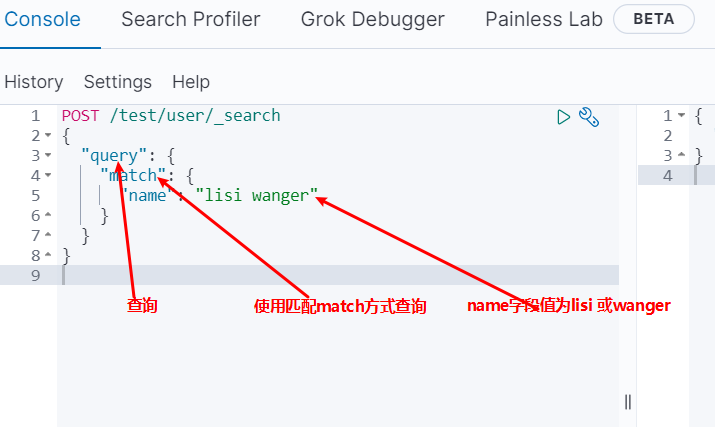
DSL查询
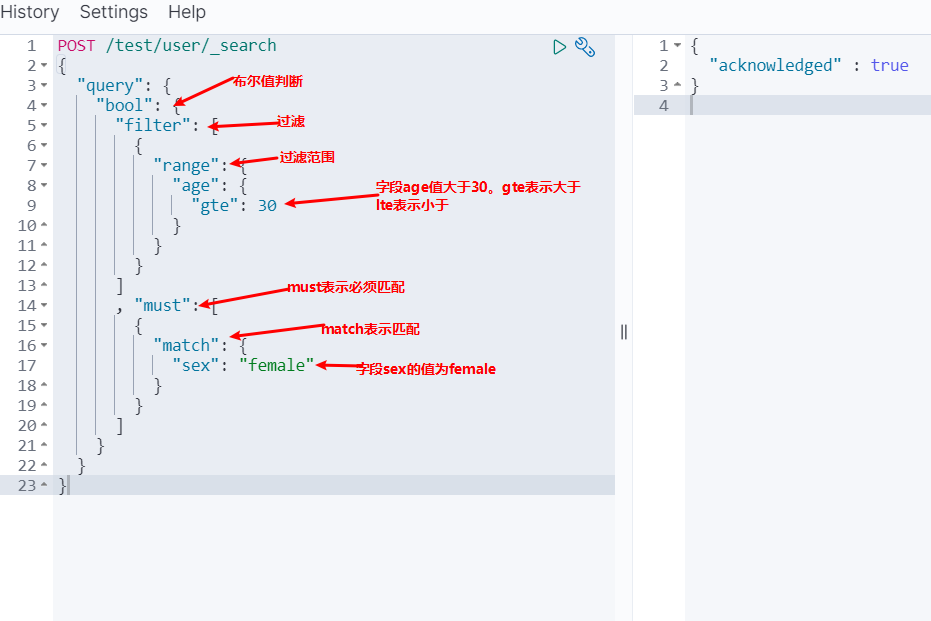
根据条件查询
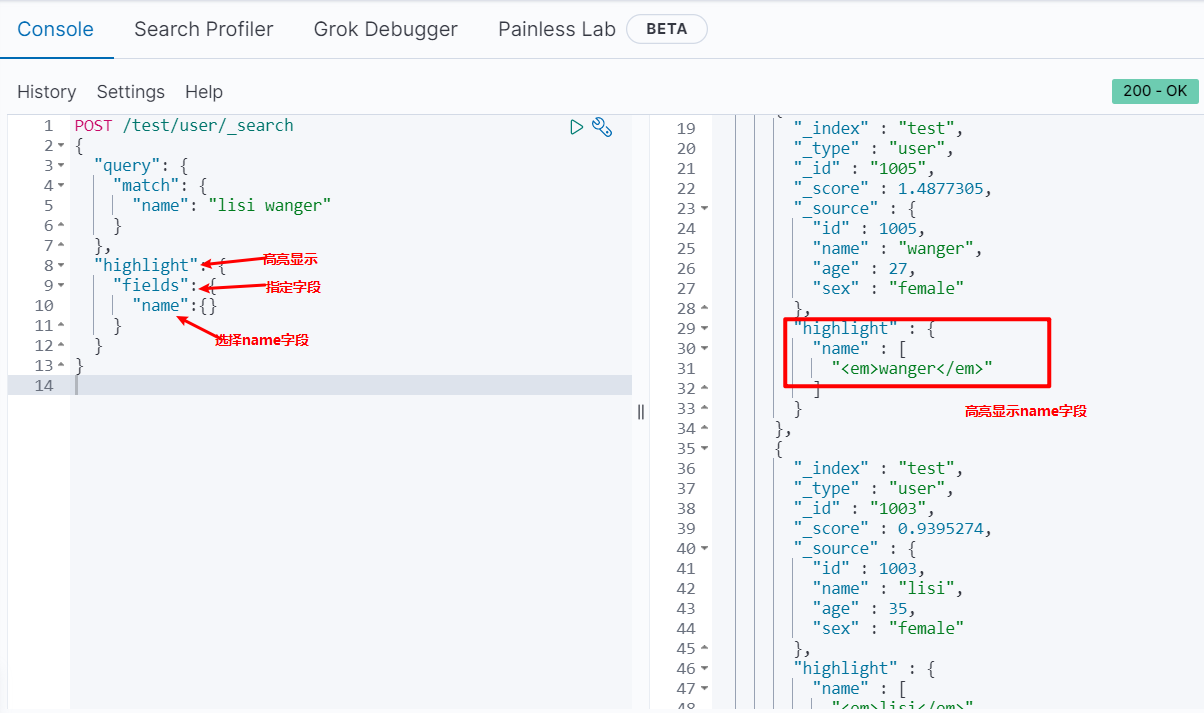
高亮显示
扩展命令
a.查询URL后加?pretty参数便于查看
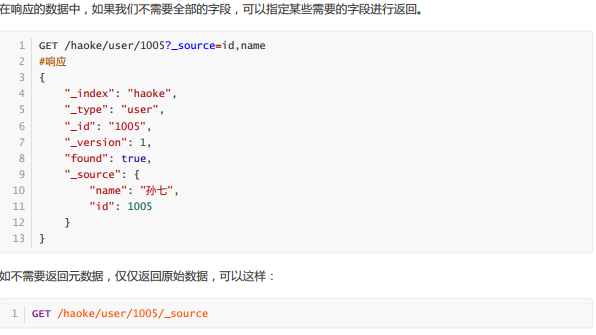
b.选择字段显示,不返回全部信息
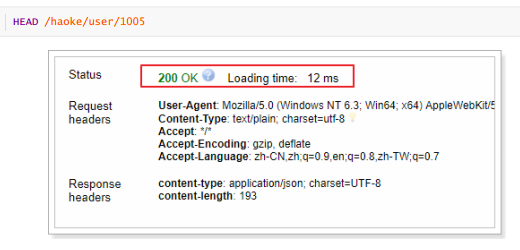
c.判断文档是否存在-HEAD方法
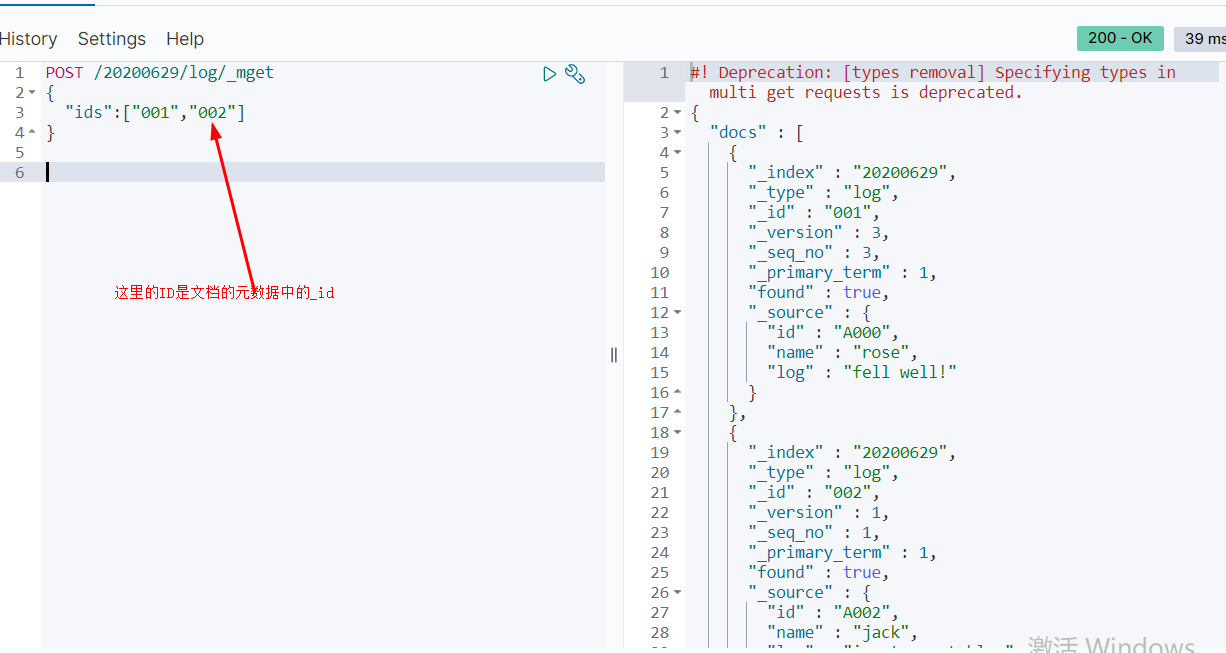
d.批量查询-mget方法
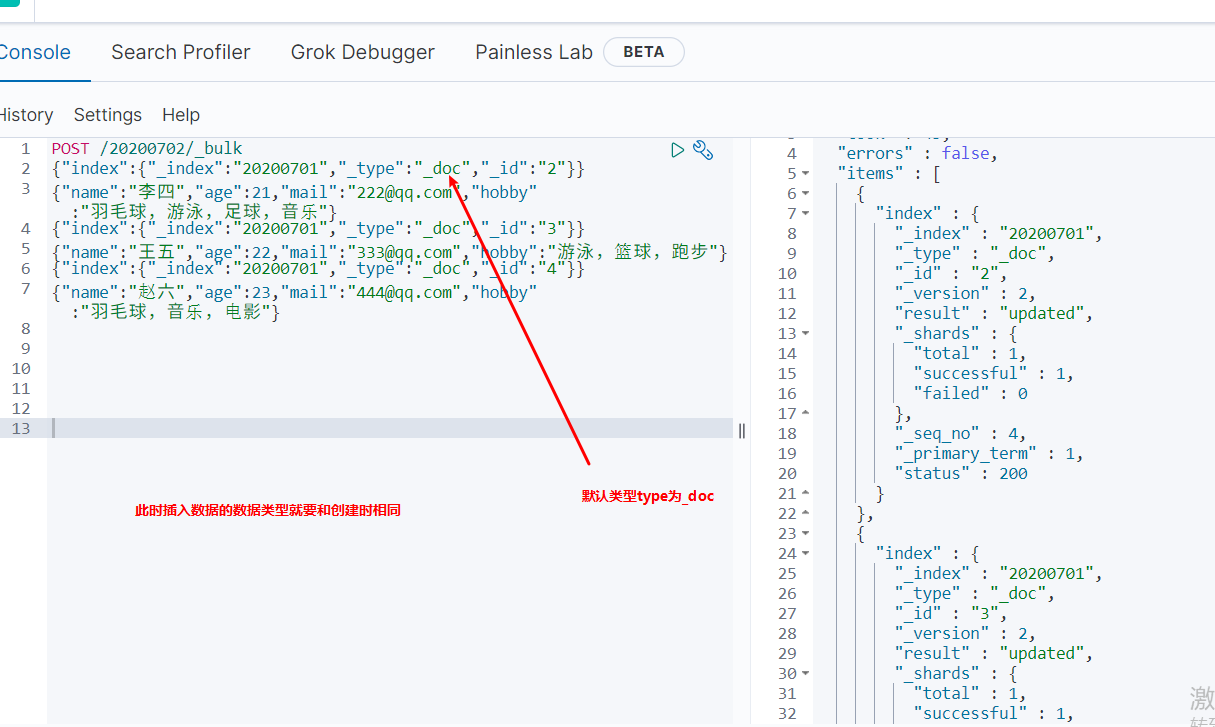
e.批量插入-bulk方法(该方法可用于批量插入,删除,变更操作)
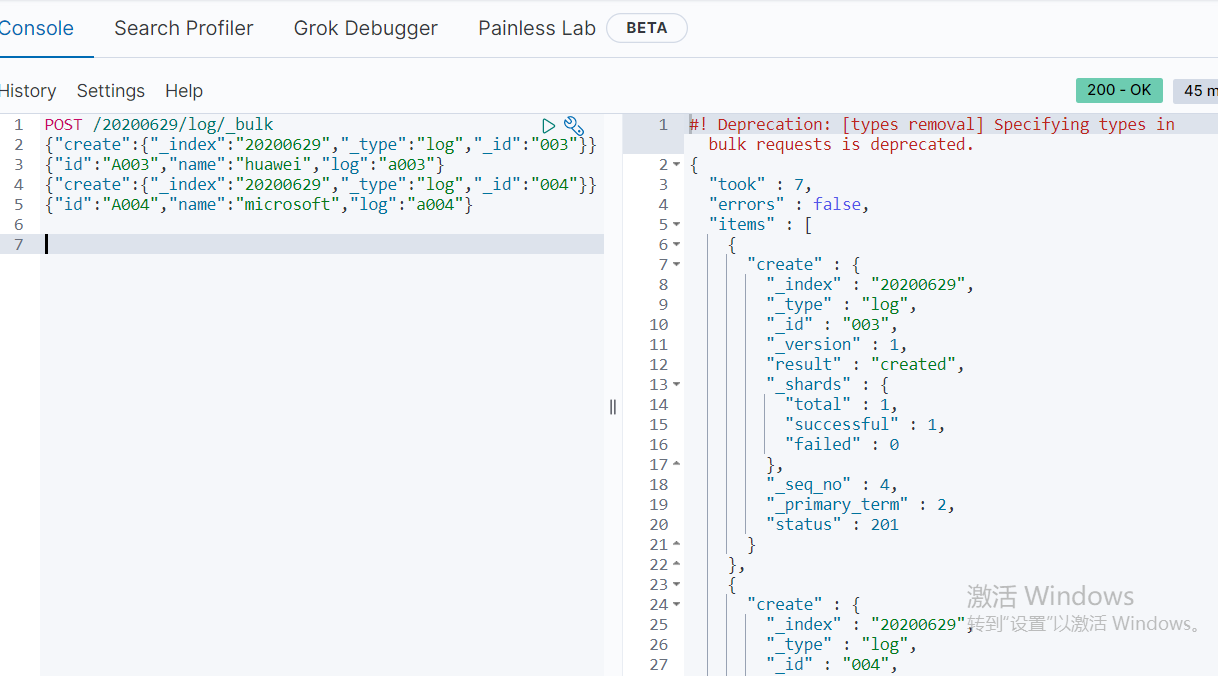
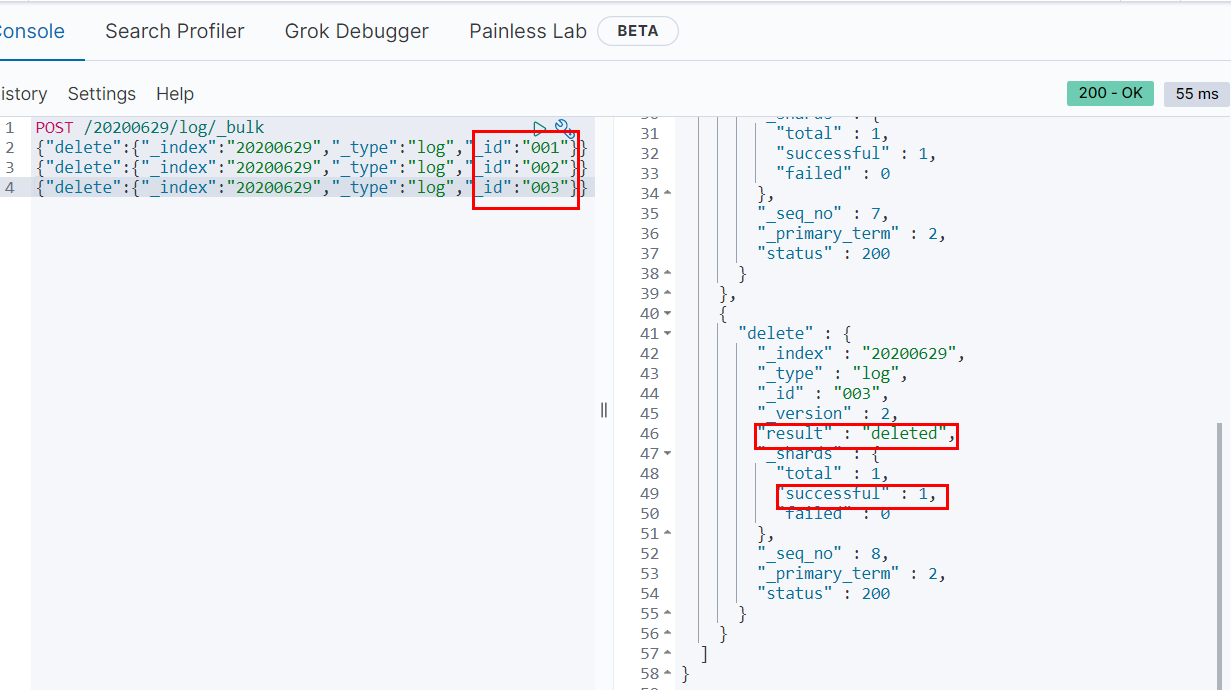
f.分页
指定每页显示的结果数以及需要跳过的条数。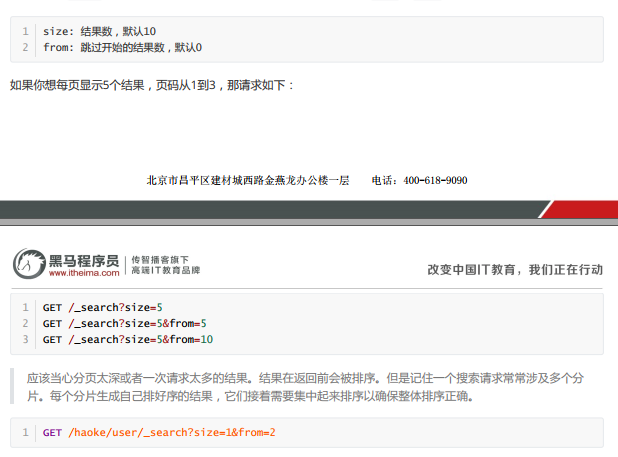
g.term查询
用于精确匹配值,如数字,日期,布尔值等。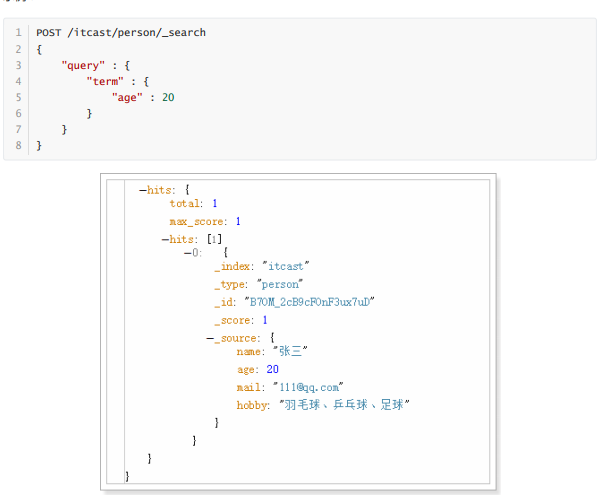
h.terms查询
与term类似,可以匹配多个条件。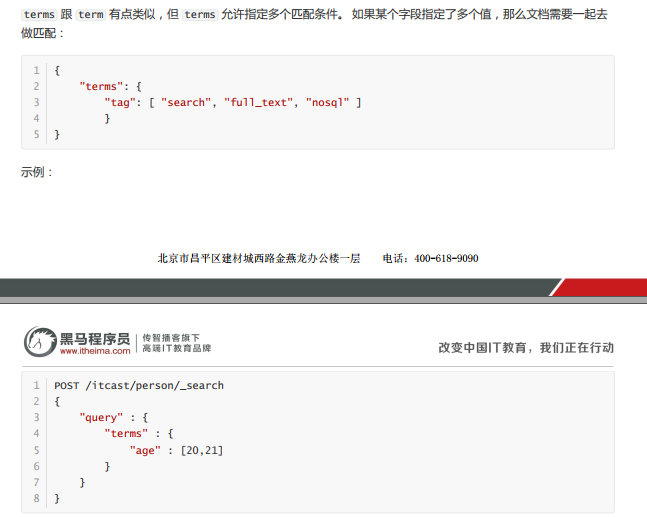
i.range查询
按照指定范围查找数据。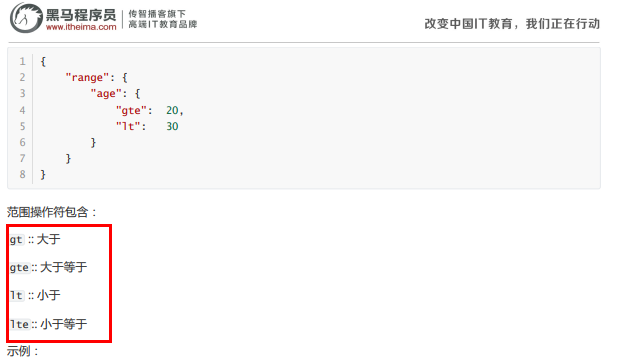
j.exists查询
查找文档中是否包含指定字段或者没有某个字段,类似于IS_NULL条件。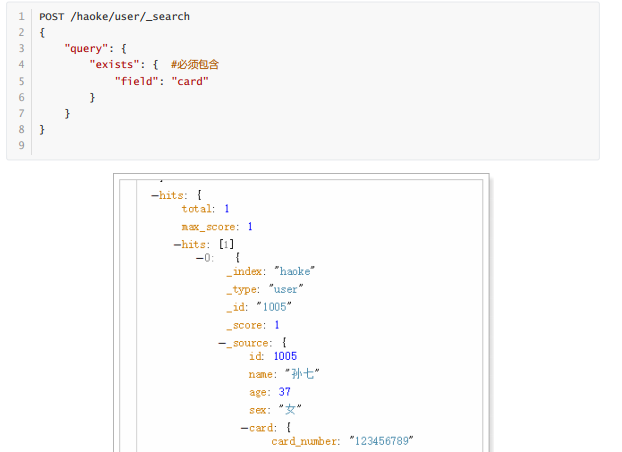
k.match查询
标志查询。如果使用match查询全文本text类字段,在查询之前会对查询条件进行分词;如果查询确切值将会直接以查询值为条件进行查询。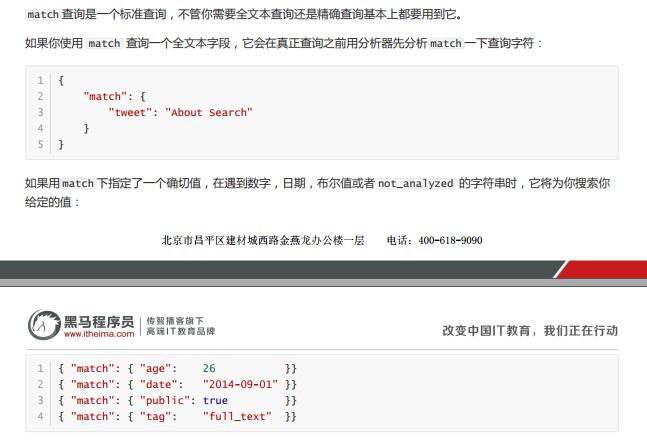
l.bool查询
布尔查询用于合并多个条件查询结果的布尔逻辑,包含以下操作符:must: 多个查询条件完全匹配,相当于 and must_not: 多个查询条件相反匹配,相当于 not should: 至少有一个条件匹配,相当于 or

m.filter过滤查询
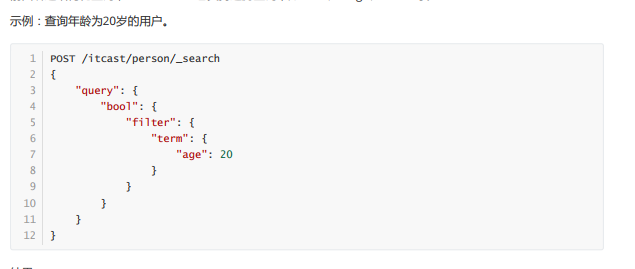
分词及搜索
相关性时评价查询于其结果间的相关程度,并根据相关程度对结果进行排名的一种方法。 分词的目的在于创建倒排索引创建索引,并设置索引的字段和映射方式
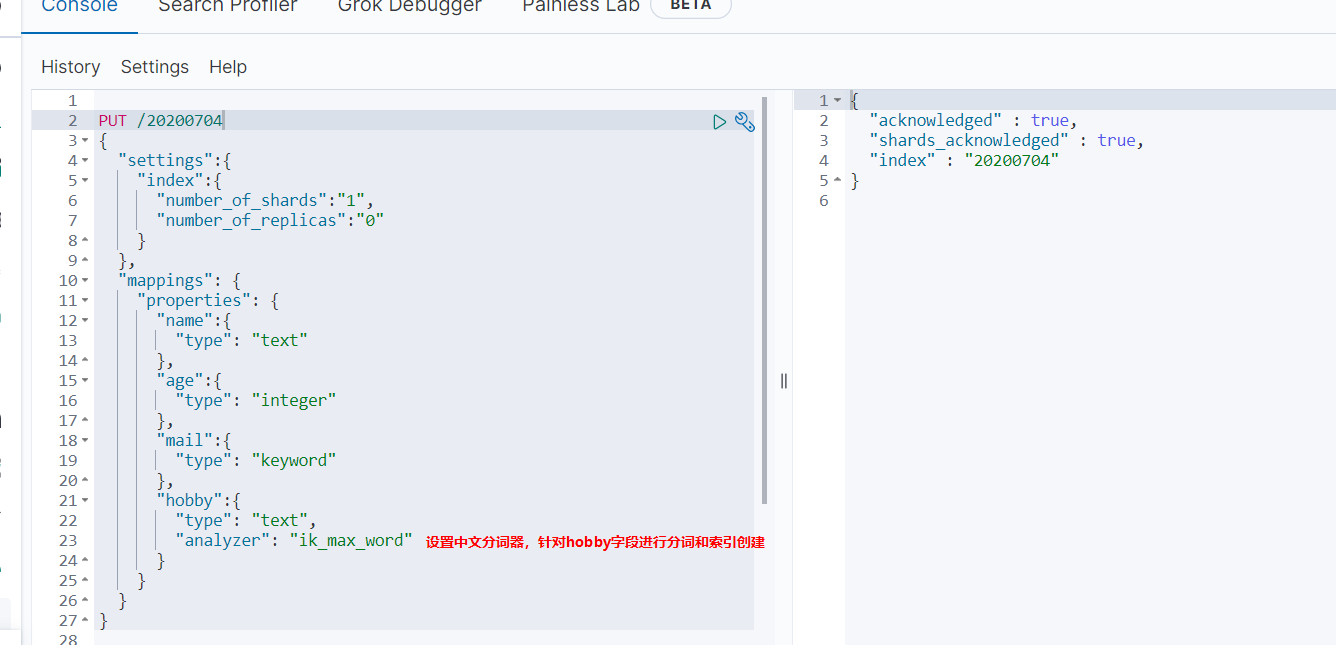
批量插入数据
单词搜索
针对单词进行搜索时,查询字符串本身也会被分词,相关度评分_score是一种结合词频,出现的文档频率,字段长度进行计算的方式。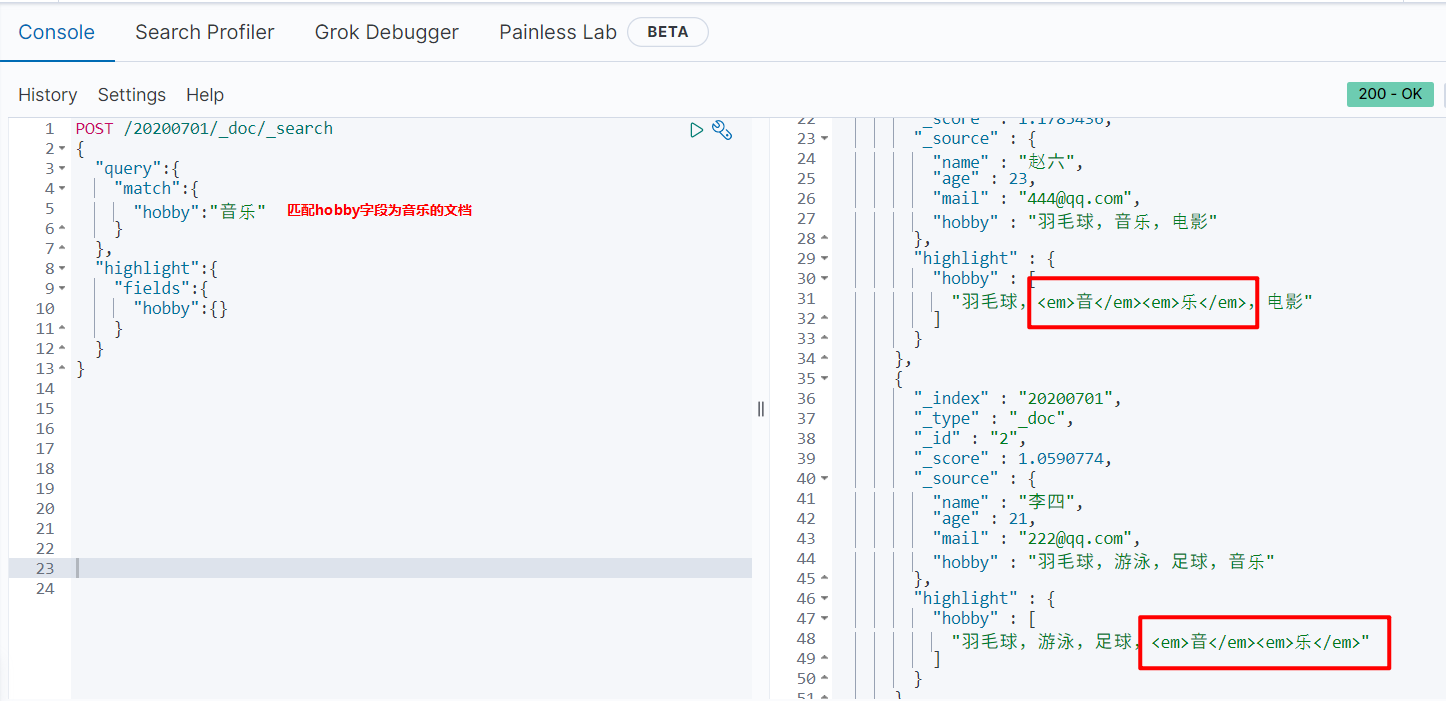
多词搜索
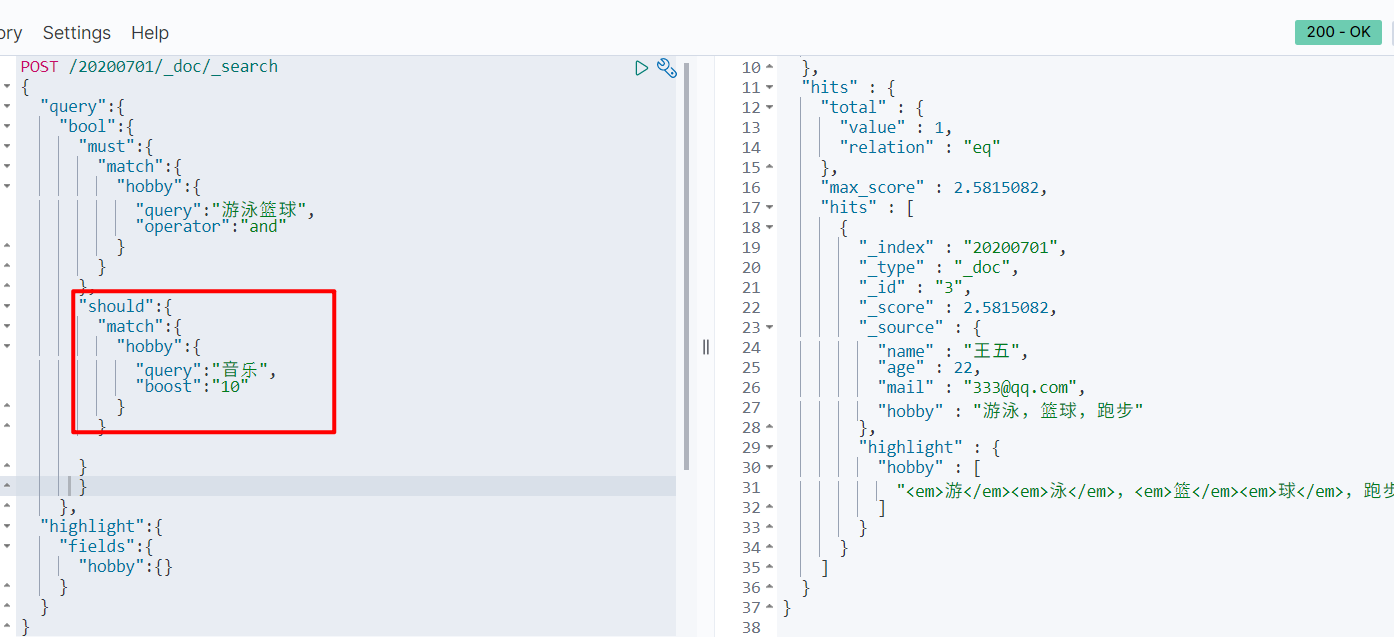
如果要想搜索包含“音乐”和足球的用户,就需要用operator指定其使用的逻辑关系或者minimun_should_match匹配度。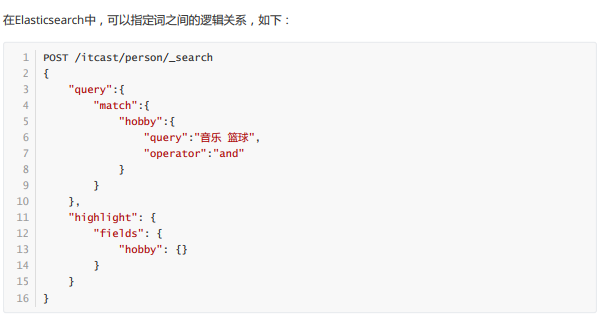

组合搜索
借助bool进行查询,其中must_not条件不影响评分,只是将不相干的文档排除;should的内容也不是必须匹配的。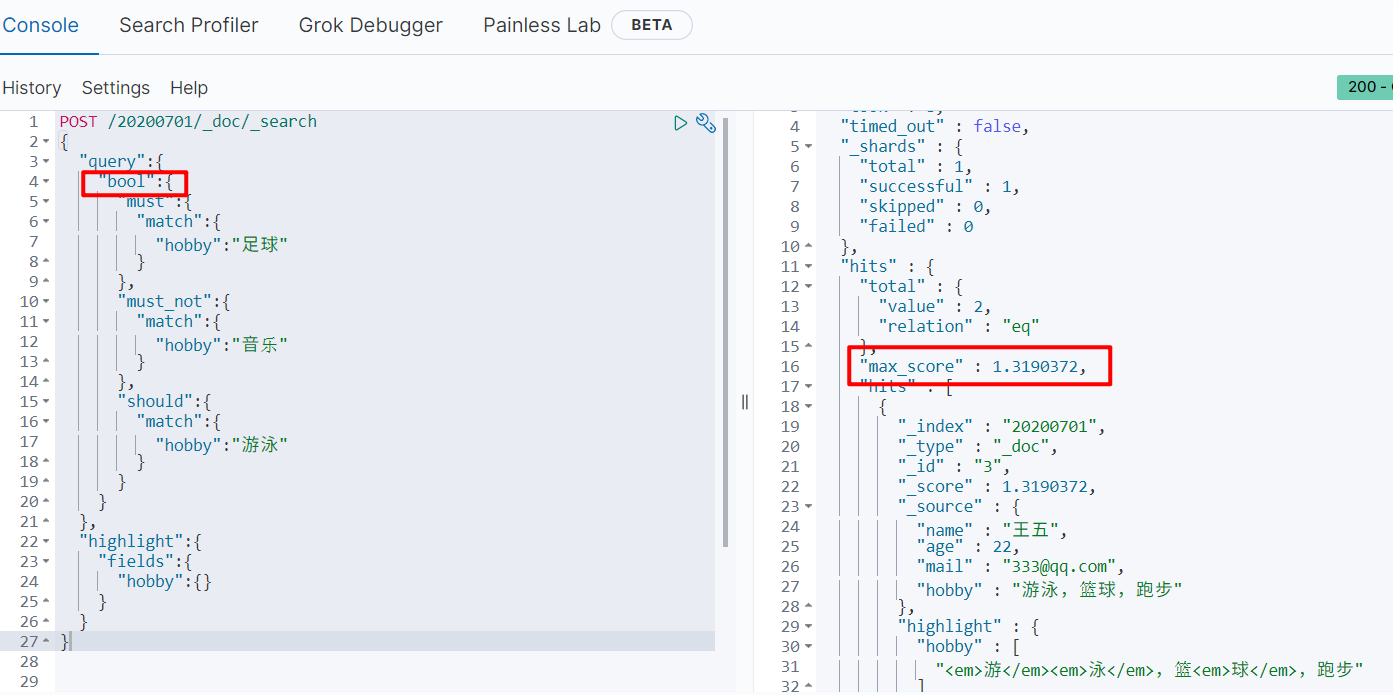
权重
对于某些重要的词增加权重,影响其文档得分。